Przyszed³ czas aby zacz±æ temat o nowym projekcie, tj. filtr cyfrowy typu FIR (filtr o skoñczonej odpowiedzi impulsowej, z ang. Finite Impulse Response) zaimplementowany w FPGA :)
W sumie nie wiem od czego tu zacz±æ, poniewa¿ matematyka stoj±ca za cyfrowym filtrowaniem i ditheringiem nie bêdzie rozwijana, ale jednak trzeba co¶ wspomnieæ aby zrozumieæ dzia³anie filtrowania czêstotliwo¶ci w domenie cyfrowej. Zacznijmy jednak od tego, ¿e zadaniem takiego filtru jest dok³adnie takie same jak zwrotnicy w kolumnie g³o¶nikowej, tj. filtrowanie danych czêstotliwo¶ci i przepuszczanie innych Ró¿nica jest jednak taka, ¿e taki filtr pracuje w domenie cyfrowej oraz ma zazwyczaj wysoki rz±d, tzw. du¿± ilo¶æ tapsów b±d¼ wspó³czynników. Taki filtr mo¿e byæ ka¿dego typu, tj. dolnoprzepustowy, górnoprzepustowy, ¶rodkowyprzepustowy czy jakikolwiek inny typ, tj. zale¿y to tylko i wy³±cznie od u¿ytych wspó³czynników. W tym wypadku bêdê skupiaæ siê na filtrze dolnoprzepustowym, poniewa¿ takim typu filtrem jest ten projekt.
Ró¿nica jest jednak taka, ¿e taki filtr pracuje w domenie cyfrowej oraz ma zazwyczaj wysoki rz±d, tzw. du¿± ilo¶æ tapsów b±d¼ wspó³czynników. Taki filtr mo¿e byæ ka¿dego typu, tj. dolnoprzepustowy, górnoprzepustowy, ¶rodkowyprzepustowy czy jakikolwiek inny typ, tj. zale¿y to tylko i wy³±cznie od u¿ytych wspó³czynników. W tym wypadku bêdê skupiaæ siê na filtrze dolnoprzepustowym, poniewa¿ takim typu filtrem jest ten projekt.
Pozwolê sobie zapo¿yczyæ grafikê filtru typu FIR aby wyjasniæ mniej wiêcej na jakiej zasadzie dzia³a taki filtr:
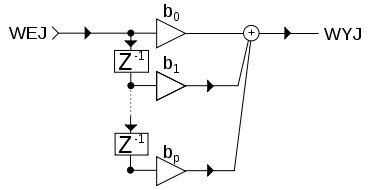
Mamy wej¶cie filtru, które w naszym wypadku jest wej¶ciem strumienia danych audio. Cz³on Z -1 to po prostu próbka audio opó¼niona o jeden, tj. ka¿da poprzednia próbka przed t± nowsz± (od najnowszej do najstarszej). Cz³ony Bx to wspó³czynniki filtru, które mno¿one s± poprzez wcze¶niejsze próbki ze strumienia audio. Wszystkie wyniki tych mno¿eñ s± potem dodawane do siebie i tak o to otrzymujemy próbkê na wyj¶ciu uk³adu
Najprostszym przyk³adem filtru FIR jest po prostu liczenie ¶redniej warto¶ci ze wszystkich poprzednich próbek. Zobaczmy na powy¿szy obrazek i za³ó¿my, ¿e wszystkie trzy cz³ony Bx maj± tak± sam± warto¶æ, tj. 1/3. Zak³adaj±c, ¿e na wej¶ciu uk³adu mamy próbki o warto¶ciach 1, 2 i 3 to matematyka stoj±ca za filtrem wygl±da nastêpuj±co: 1/3 * 1 + 1/3 * 2 + 1/3 * 3 = 2 Inaczej pisz±c w przypadku takich wspó³czynników liczymy tylko ¶redni± na bazie N próbek wej¶ciowych. Inn± nazw± takiego filtru to ¶rednia ruchoma, tj. z ang. moving-average (https://pl.wikipedia.org/wiki/¦rednia_ruchoma). Ciekawe jest to, ¿e taki filtr ju¿ kiedy¶ stworzy³em, ale nie sam filtr i nie cyfrowo, ale wbudowany w przetwornik D/A, tj. temat z "NOS" DAC:
https://diyaudio.pl/showthread.php/2...-dobrze-zrobiæ
Przyk³adowy FIR oraz powy¿szy przetwornik D/A dzia³aj± dok³adnie tak samo, ale jeden dzia³a w domenie cyfrowej a drugi w analogowej Taki filtr jest tzw. ekstrapolatorem rzêdu pierwszego. Niestety jego zdolno¶æ filtrowania i rekonstrukcji sygna³u pozostawia wiele do ¿yczenia, wiêc jest to generalnie tylko ciekawostka, ale ma te¿ swoje plusy (szczególnie przy strumieniu DSD). My¶lê, ¿e warto tutaj wspomnieæ te¿ o tym, ¿e ekstrapolatorem rzêdu zerowego jest zwyczajny przetwornik R-2R w formie NOS Poni¿szy obrazek przedstawia ró¿nicê miêdzy ekstrapolatorem rzêdu zerowego (NOS) a ekstrapolatorem rzêdu pierwszego (liniowa interpolacja) oraz ich odpowiedzi impulsowe wraz z charakterystyk± czêstotliwo¶ciow±:
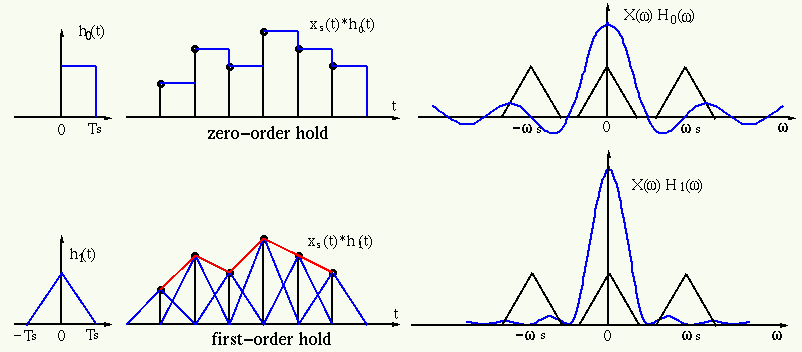
Naprawdê nie ma co siê rozpisywaæ, poniewa¿ pisanie o filtrach FIR mo¿e i byæ ciekawe, ale zbêdne i czasoch³onne. Temat dotyczy samego projektu takiego filtru a nie tego jaka matematyka za tym wszystkim stoi, wiêc postaram siê jeszcze po szybko¶ci wspomnieæ o interpolacji, filtrowaniu sin(x) / x i ditheringu oraz przej¶æ do samego projektu filtru na FPGA.
W nazwie temat wspomnia³em, ¿e zaprojektowany filtr cyfrowy jest typu interpolacyjnego, tj. takiego, który zwiêksza oryginaln± czêstotliwo¶æ próbkowania, przyk³adowo 44.1 kHz, do zadanej czêstotliwo¶ci, np. w moim wypadku jest to 705.6 kHz. Z prostej matematyki mo¿na wywnioskowaæ, ¿e filtr interpoluje 16-krotnie (44.1 kHz * 16 = 705.6 kHz). Zacznijmy jednak od tego co to jest interpolacja. Interpolacja jest to proces wyznaczenia pewnej funkcji, która przyjmuje takie same warto¶ci w zadanej przedziale w którym s± ju¿ wyznaczone pewne punkty. Sygna³ audio zapisany jest jako warto¶æ amplitudy (punkt na osi Y) w pewnych odstêpach czasowych (o¶ X, np. 44.1 kHz). Inaczej pisz±c zadaniem interpolacji jest po prostu wyznaczenie dodatkowych punktów pomiêdzy istniej±cymi ju¿ punktami. Taki zabieg najlepiej przedstawiæ na obrazku, wiêc zobaczmy poni¿ej:
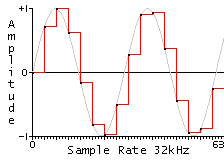
Czerwony to sygna³ taki jaki mamy zapisany w pliku i zrekonstruowany na przetworniku R-2R w formie NOS (ekstrapolator rzêdu zerowego). Czarny to ten sam sygna³, ale interpolowany do nieskoñczenie wy¿szej czêstotliwo¶ci w celu odtworzenia wiêkszej ilo¶ci punktów oryginalnego zapisu. Inaczej pisz±c taki zabieg w praktyce to po prostu rekonstrukcja sygna³u wraz z filtrowaniem dolnoprzepustowym. Interpolacja w formie cyfrowej to dwa zabiegi, tj. wrzucenie próbek o zerowej amplitudzie do sygna³u tak aby zwiêkszyæ czêstotliwo¶æ oraz filtrowanie dolnoprzepustowe w celu pozbycia siê odbiæ sygna³u, które powsta³y z powodu zwiêkszenia próbkowania. Na poni¿szych obrazkach mo¿na zobaczyæ jak to w praktyce wygl±da:
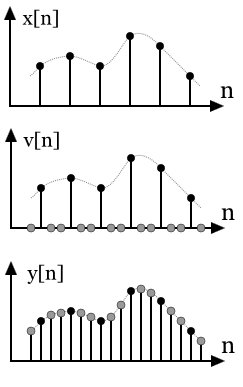
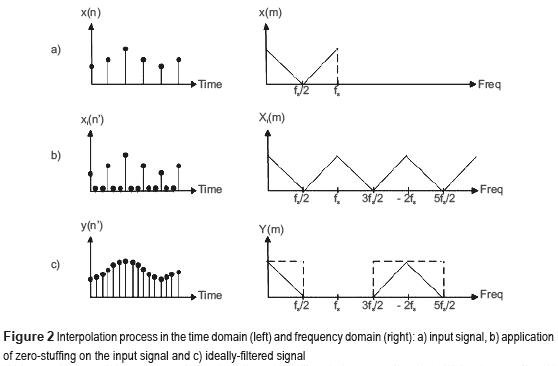
W pierwszym obrazku na samej górze posiadamy sygna³ oryginalny, dyskretny (czarne punkty) oraz ci±g³y (szara linia). Sygna³u w formie ci±g³ej nie da siê zapisaæ, poniewa¿ wymaga³oby to nieskoñczonej ilo¶ci miejsca, wiêc w praktyce zapisujemy tylko sygna³ w formie dyskretnej (próbkowany w równych odstêpach czasu, np. 44.1 kHz). W celu odtworzenia oryginalnego sygna³u musimy zwiêkszyæ ilo¶æ próbek, które pozwol± nam zamieniæ sygna³y dyskretny na sygna³ ci±g³y (analogowy). W tym celu wrzucamy próbki o warto¶ci 0 pomiêdzy ju¿ istniej±ce próbki (drugi wykres). Taki zabieg pozwoli³ nam faktycznie zwiêkszyæ próbkowania, ale niestety wprowadzi³ te¿ odbicia sygna³u. W praktyce podczas próby odtworzenia takiego sygna³u otrzymujemy sygna³ powielony wzglêdem "lustra", które tworzy siê na wielokrotno¶ci oryginalnej czêstotliwo¶ci próbkowania (44.1 kHz). Ten problem mo¿na zobaczyæ na drugim obrazku po prawej stronie gdzie widnieje wykres w domenie czêstotliwo¶ciowej. W celu eliminacji tych odbiæ stosuje siê filtrowanie dolnoprzepustowe, które w praktyce przesuwa odbicia na wy¿sz± czêstotliwo¶æ gdzie mo¿na ju¿ spokojnie filtrowaæ filtrem analogowym z niskim rzêdem. Inaczej pisz±c czym wiêksza interpolacja tym dalej przesuwane s± odbicia oryginalnego sygna³u.
No i w sumie to tyle wystarczy na temat samej interpolacji, wiêc na szybko¶ci przejd¼my jeszcze do filtrowania dolnoprzepustowego funkcj± sin(x) / x. W przetwarzaniu sygna³u u¿ywa siê tylko funkcji sin(x) / x do filtrowania dolnoprzepustowego, poniewa¿ z matematycznego punktu widzenia jest ona idealnym filtrem dolnoprzepustowym (z ang. brick-wall). Wynika to z faktu, ¿e odpowied¼ czêstotliwo¶ciowa funkcji sin(x) / x jest funkcj± prostok±tn±:
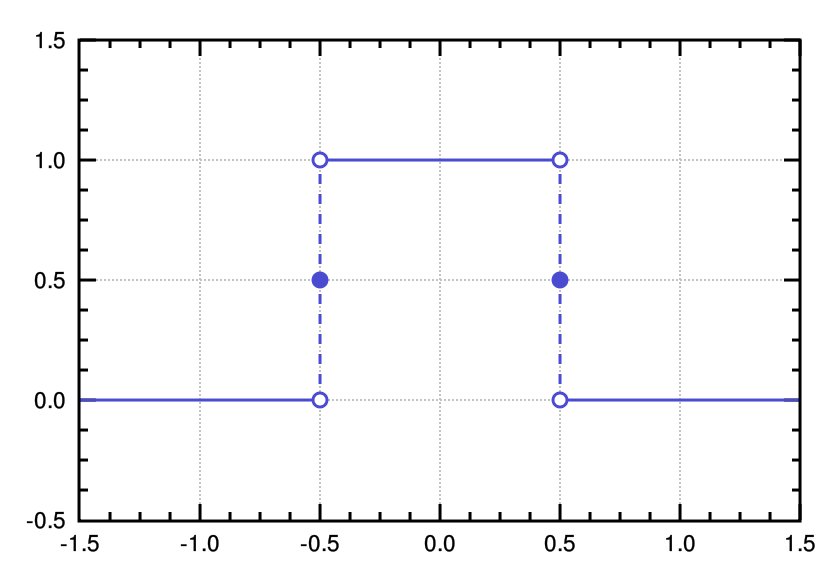
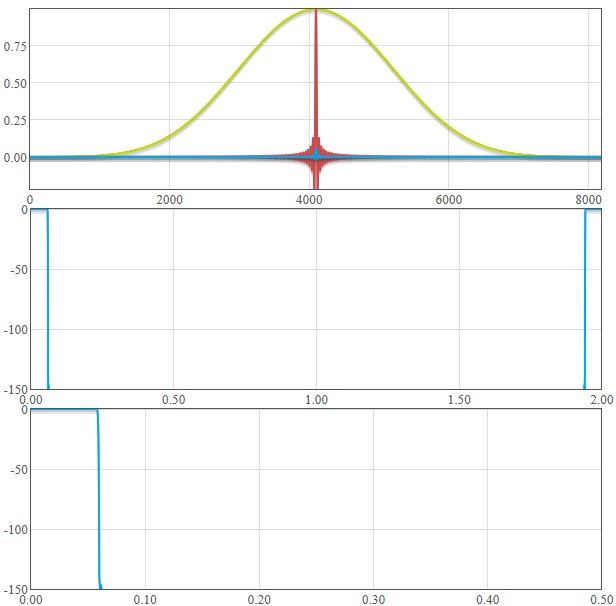
Oznacza to w praktyce tyle, ¿e przepuszcza idealnie zadane czêstotliwo¶ci a wszystkie poza wyznaczon± odpowiedzi± czêstotliwo¶ciow± po prostu usuwa. Normalnie idealny filtr, ale nie ma tak ³atwo Niestety funkcja sin (x) / x jest nieskoñczona, wiêc nie da siê jej przedstawiæ w formie praktycznego filtru cyfrowego. W tym celu u¿ywa siê metody tzw. okna czasowego (z ang. windowing), który pozwala nam "wygasiæ" funkcjê po pewnym okresie, która w praktyce jest nieskoñczona. Przyk³adowo tak± funkcj± okna czasowego mo¿e byæ okno Kaisera (ja takiego u¿y³em do wyznaczenia wspó³czynników mojego filtru sin (x) / x). Okno Kaisera wygl±da jak na poni¿szym obrazku:
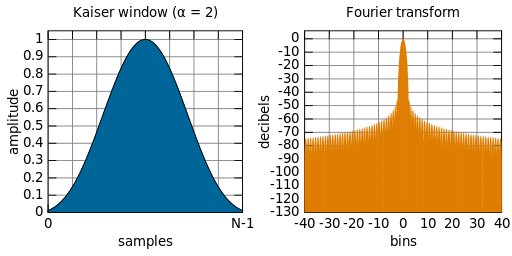
Teraz zobaczmy sobie co takie okno czasowe mo¿e zdzia³aæ z nieskoñczona funkcj± sin (x) / x:
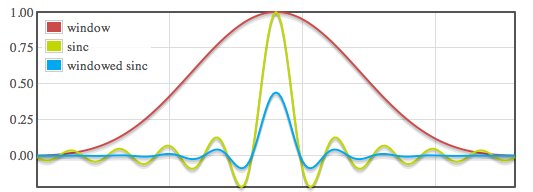
Czerwony wykres - okno czasowe.
Zielony wykres - nieskoñczona funkcja sin(x) / x.
Niebieski wykres - funkcja sin(x) / x po zastosowaniu okna czasowego.
Taki zabieg w praktyce pozwala zastosowaæ funkcjê sin(x) / x do filtrowania Oczywi¶cie wprowadza to pewne b³êdy filtrowania i taki filtr nigdy nie bêdzie idealny jak sama funkcja sin(x) / x, ale zwiêkszaj±c ilo¶æ wspó³czynników (dyskretnie zapisanego sygna³u sin(x) / x po oknie czasowym) mo¿na d±¿yæ do tej idealnej odpowiedzi czêstotliwo¶ciowej. Niestety trzeba te¿ pamiêtaæ o tym, ¿e w praktyce mamy ograniczon± ilo¶æ pamiêci w której mo¿emy zapisaæ wspó³czynniki, wiêc wprowadza to dodatkowe b³êdy kwantyzacji (cyt. "nieodwracalne nieliniowe odwzorowanie statyczne zmniejszaj±ce dok³adno¶æ danych przez ograniczenie ich zbioru warto¶ci").
No i mo¿na zacz±æ filtrowaæ! No prawie, poniewa¿ jako, ¿e pracujemy na dyskretnych sygna³ach a nie na ci±g³ych i do tego jeszcze mamy do czynienia z b³êdami kwantyzacji to jeszcze dosyæ wa¿n± rzecz± przy takim projekcie jest tzw. dithering podczas redukcji bitów wyj¶ciowego s³owa. Dlaczego redukcji? W praktyce nasz przetwornik D/A operuje przyk³adowo na s³owach audio o d³ugo¶ci 18 bitów. Zak³adaj±c, ¿e nasze s³owo wej¶ciowe to 24 bitowy sygna³ audio oraz sam fakt, ¿e te s³owo przechodzi filtrowanie w którym wystêpuje mno¿enie, powoduje, ¿e zale¿nie od ilo¶ci bitów wspó³czynników filtru, które mog± przyk³adowo mieæ 32 bity, otrzymujemy wynik na poziomie 56 bitów. No dobra, ale mno¿ymy 24 bitow± liczbê przez 32 bitow± liczbê, wiêc jakim cudem mamy wynik na 56 bitach? Taka po prostu jest matematyka Mno¿±c dwie liczby X oraz Y o d³ugo¶ci bitów odpowiednio 24 oraz 32 wynik tego zabiegu wymaga 56 bitów do zapisu. Zreszt±, nawet jakby¶my nie musieli nic mno¿yæ to i tak musimy zredukowaæ 24 bity do 18 bitów, które przyjmuje przetwornik. Taki zabieg jest wymagany, poniewa¿ b³êdy kwantyzacji sygna³u wprowadzane przez redukcjê bitów (np. uciêcie ostatnich bitów) s± wprowadzane w sam sygna³ audio. Dither to najprostsza metoda przeniesienia energii tych b³êdów kwantyzacji na losowy szum w sygnale audio. Inaczej pisz±c specjalnie dodajemy szum do sygna³u audio Najlepiej bêdzie to pokazaæ na przyk³adzie:
Bez ditheringu:
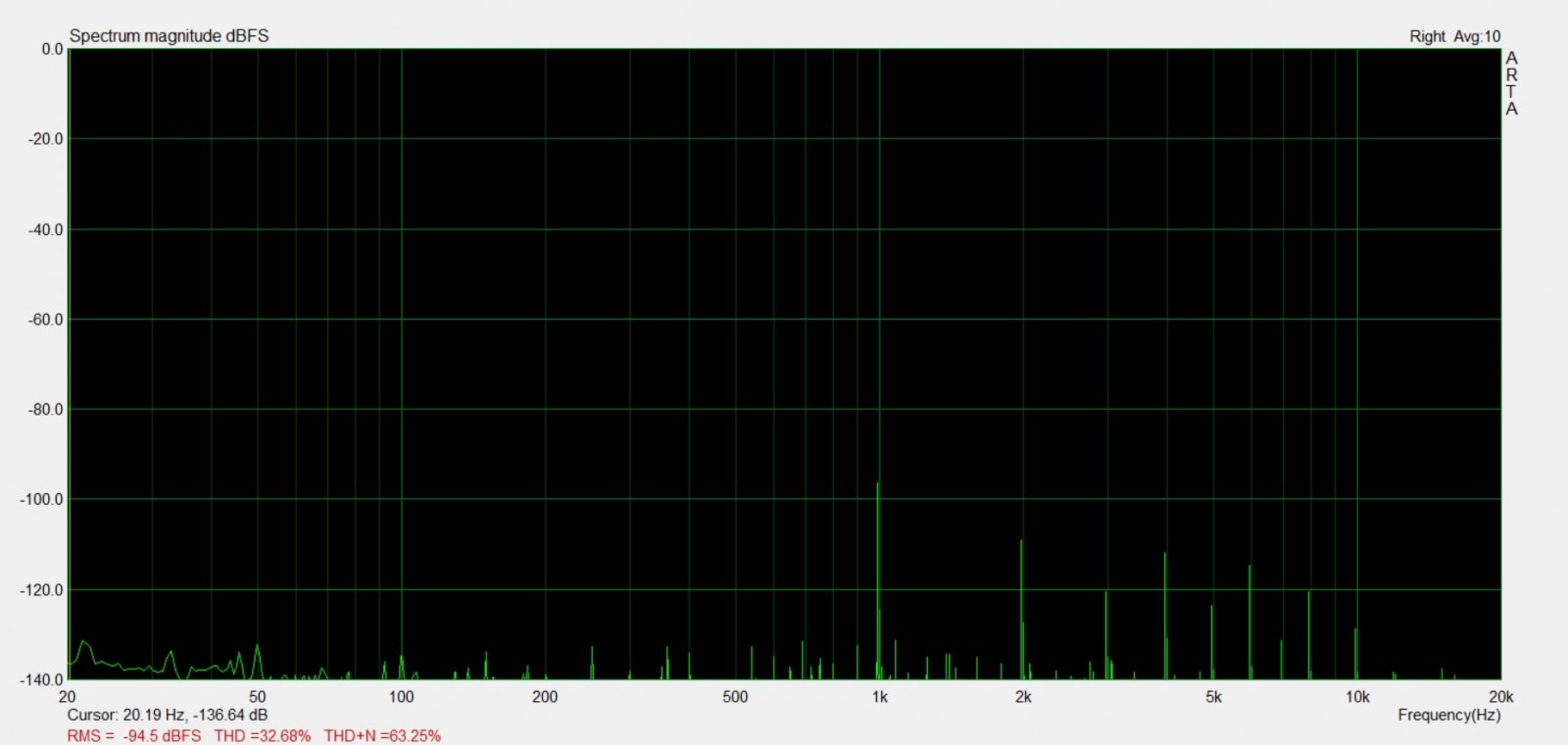
Z ditheringiem:
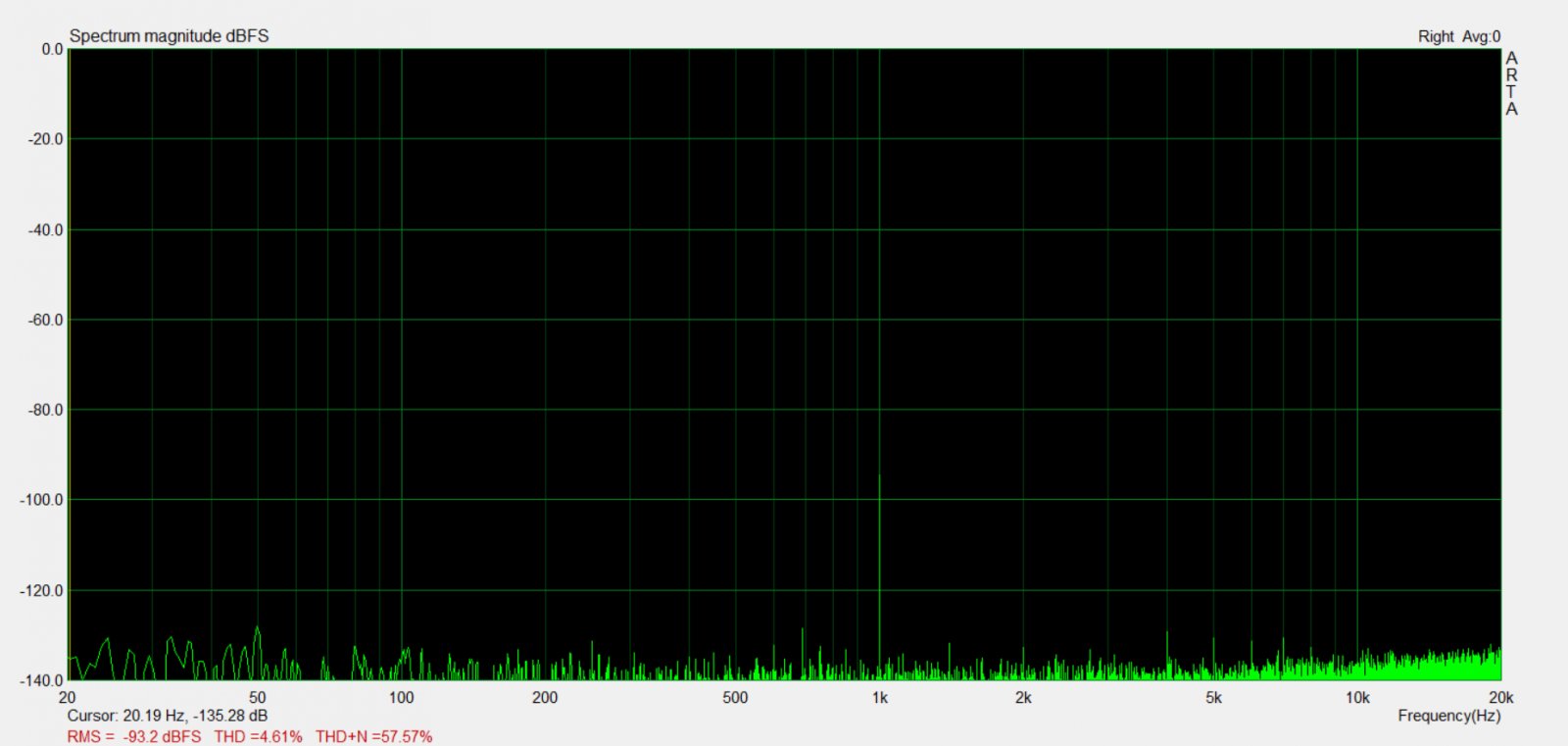
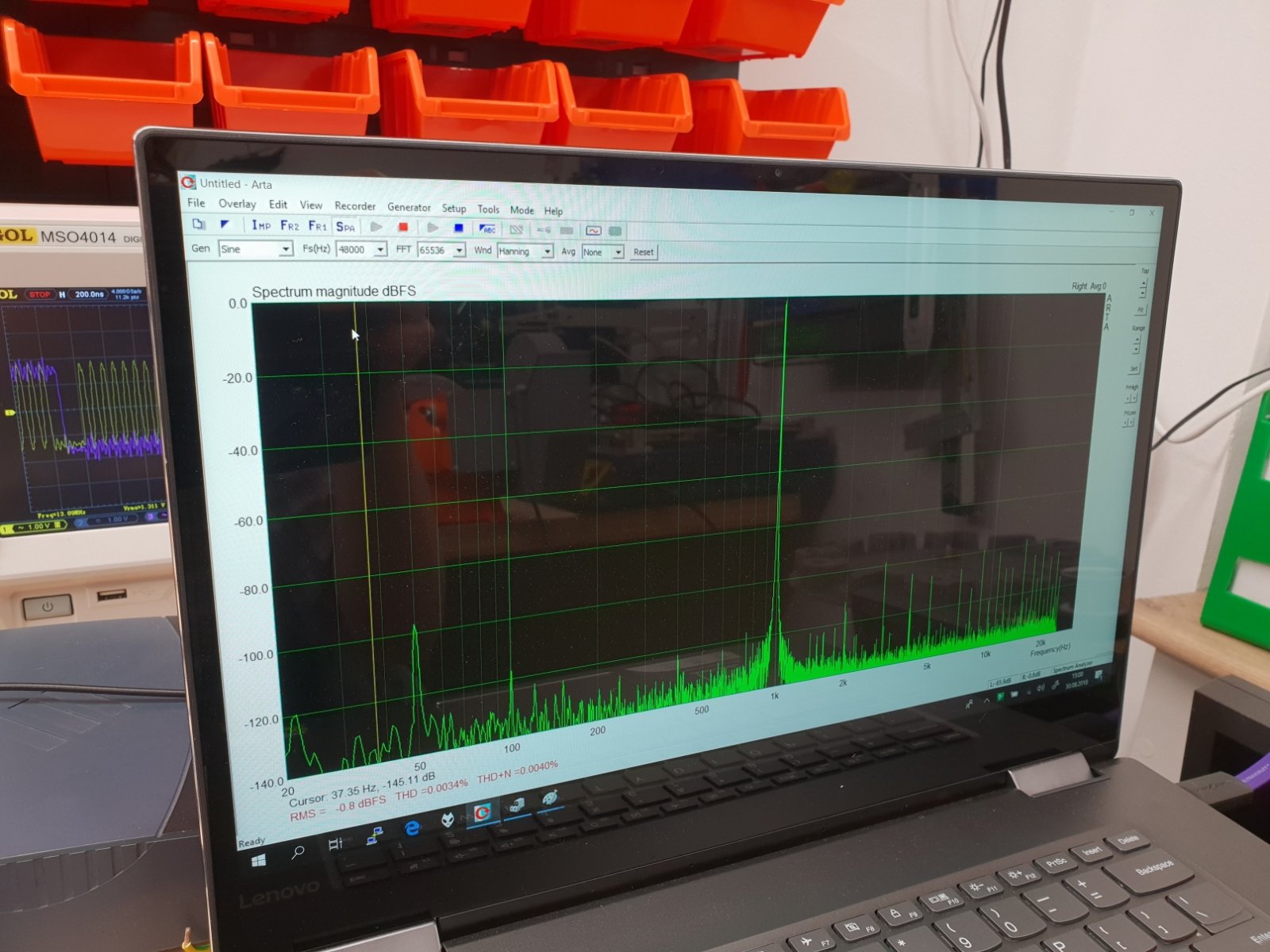
Na przyk³adzie tego filtra zosta³o pokazane jak dither mo¿e pomóc przy odwzorowaniu sygna³u -96 dBFS na 18 bitowym przetworniku :) Na górze te¿ jest ¶rednia z 10 pomiarów, wiêc koniec koñców ró¿nica w szumie jest ¿adna :)
Dithering wymaga generatora liczb pseudolosowych, poniewa¿ chcemy aby nasz szum by³ po prostu losowy. No prawie, poniewa¿ nie potrzebujemy losowo¶ci w sensie nieprzewidywalno¶ci samych generowanych liczb, ale ci±gu generowanych warto¶ci, które maj± rozk³ad jednostajnie ci±g³y, tj. taki dla którego wyst±pienie danej liczby z danego przedzia³u jest tak samo prawdopodobne jak dla ka¿dej innej z tego samego przedzia³u. Pewn± w³asno¶ci± rozk³adu jednostajnie ci±g³ego jest to, ¿e dodanie dwóch takich losowych liczb zamienia rozk³ad na trójk±tny, czyli taki, którego gêsto¶æ prawdopodobieñstwa rozk³ada siê w formê trójk±tn± gdzie jego wierzcho³ek to liczby, które maj± najwiêksz± szansê na trafienie. Na poni¿szym obrazku X oraz Y to rozk³ad jednostajnie ci±g³y a Z to trójk±tny:
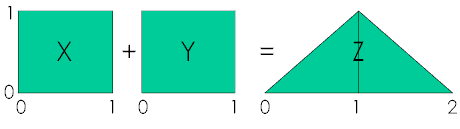
Rozk³ad trójk±tny jest ¶wietny do ditheringu audio, poniewa¿ zazwyczaj maj±c jedynkê chcemy aby dalej to by³a jedynka, tj. z du¿ym prawdopodobieñstwem, ale aby nie by³o to równomierne. Inaczej pisz±c ditheringiem mo¿na nazwaæ operacjê posiadania liczby X oraz losowania liczby Y chc±c trafiæ tak, aby X ~ Y, ale jednak nie chcemy znanej liczby X, ale nowej liczby Y, która ma du¿e prawdopodobieñstwo trafiæ blisko X
¬ród³em takiej pseudo losowo¶ci do wygenerowania rozk³adu trójk±tnego w FPGA mo¿e byæ rejestr przesuwaj±cy z liniowym sprzê¿eniem zwrotnym, który tak¿e zosta³ zaimplementowany w tym projekcie. Zaimplementowany rejestr ma okres 2^47 i pracuje z zegarem MCLK, który mo¿e tykaæ z czêstotliwo¶ci± do 49.152 MHz. Z prostej matematyki wynika, ¿e taki rejestr zanim zacznie siê powtarzaæ z liczbami to minie ponad miesi±c ci±g³ej pracy, wiêc tym bardziej jest wystarczaj±cy do generowania pseudo losowych warto¶ci Zreszt±, po pomiarach z ditherem i bez mo¿na jasno wywnioskowaæ, ¿e losowo¶æ spe³nia pewne wymogi i energia b³êdu kwantyzacji jest zamieniana na energiê szum.
No dobra, mo¿e koniec ju¿ samej teorii. My¶la³em, ¿e skrócê to wszystko dosyæ znacz±co omijaj±c pewne rzeczy, ale teraz jak na to patrzê to widzê, ¿e nawet mocno skrócony opis potrafi byæ rozleg³y w takiej tematyce.
_____________________________________
W ka¿dym wypadku przejd¼my do samego projektu filtru, który zosta³ zaimplementowany w FPGA (bezpo¶rednio programowalna macierz bramek) w formie RTL (opisu sprzêtu w formie logiki w VHDL'u). FPGA u¿yte w tym projekcie to Spartan-6 XC6SLX9 w obudowie TQFP-144. W innych projektach zazwyczaj u¿ywam Spartan-3 XC3S50AN, poniewa¿ posiadam ich jeszcze trochê i sobie ceniê ich prostotê oraz wbudowany FLASH do konfiguracji. Niestety do tego projektu taki Spartan-3 jest po prostu za s³aby i nie posiada odpowiednich jednostek do implementacji sensownego filtru cyfrowego. Pewnie, jaki¶ filtr mo¿na tam zmie¶ciæ, ale po co tworzyæ nastêpne dziadostwo, które w sumie nie wiele wiêcej wprowadza ni¿ gotowe uk³ady dostêpne na rynku od lat 90. Zaprojektowany filtr implementuje zarówno interpolacjê jak i decymacjê. Matematycznie wykonuje on 16-krotn± interpolacjê dla ka¿dej wej¶ciowej czêstotliwo¶ci (tj. od 44.1 kHz do 768 kHz). W praktyce wygl±da to tak, ¿e sygna³ 768 kHz te¿ jest interpolowany 16-krotnie (do 12.288 MHz), ale koniec koñców sygna³ jest decymowany do zadanej warto¶ci (odrzucanie próbek). Operacja interpolacji i decymacji na tych samych wspó³czynnikach skraca siê, wiêc w praktyce to wygl±da tak, ¿e filtr nie liczy próbek, które i tak zostan± odrzucone
Na rynku mamy wiele uk³adów filtrów cyfrowych takich jak SAA7220, DF1706, SM5847, itp. Wszystkie te uk³ady s³u¿± do tego samego, tj. interpolacji sygna³u audio. W praktyce niektóre s± lepsze a niektóre gorsze, wiêc ka¿dy bêdzie gra³ inaczej. Przyk³adowo SAA7220 jest chyba najlepszym przyk³adem kiepskiego filtru zrobionego po tanio¶ci Wspó³czynniki 12-bitowe, s³owo wej¶ciowe maksymalnie do 16 bitów, bardzo ma³y akumulator (du¿o b³êdów zaokr±glenia wyników mno¿enia) oraz brak ditheringu. Ewidentnie widaæ, ¿e to co stracimy w kiepskim filtrze cyfrowym na pewno nie uda nam siê nadrobiæ przetwornikiem D/A. Filtry cyfrowe takie jak DF1706 czy SM5847 s± ju¿ znacz±co lepsze i to widaæ, ale ich kaskadowana interpolacja na ró¿nych wspó³czynnikach raczej do mnie nie przemawia. Filtr taki jak SM5847 interpoluje 8-krotnie w 3 fazach, tj. pierwsza faza posiada 169 wspó³czynników (fs do 2fs), druga faza ju¿ tylko 29 wspó³czynników (2fs do 4fs) oraz ostatnia faza z 17 wspó³czynnikami (4fs do 8fs). Tak po prostu ³atwiej by³o go zaprojektowaæ, ale niekoniecznie lepiej sonicznie. Filtr cyfrowy przedstawiony w tym temacie interpoluje i decymuje na tych samych wspó³czynnikach, wiêc nie wa¿ne jaka jest czêstotliwo¶æ wej¶ciowa to zawsze te same wspó³czynniki u¿ywane s± do stworzenia wyj¶ciowego strumienia Mój filtr ma sta³± warto¶æ polifazy oraz interpolacji, która wynosi 16. Oznacza to w sumie tyle, ¿e ka¿da nowa próbka audio tworzona jest na bazie 512 poprzednich próbek (8192 / 16 = 512). Sygna³ powinien byæ perfekcyjnie zrekonstruowany na bazie poprzednich próbek.
W danej chwili wspó³czynniki filtru wraz z u¿ytym oknem oraz pasmem przepustowym wygl±daj± nastêpuj±co:
Trzeba pamiêtaæ, ¿e filtr jest interpolacyjny, wiêc pasmo przepustowe liczy siê na bazie docelowej czêstotliwo¶ci.
W praktyce nie ma co siê do tych wspó³czynników przywi±zywaæ, poniewa¿ zale¿nie od sonicznych do¶wiadczeñ mo¿na w chwilê za³adowaæ nowe i znowu ods³uchiwaæ
Poni¿ej parê zdjêæ, które ju¿ wrzuca³em w budowanie na ekranie, ale warto te¿ pokazaæ je w tym temacie:
Rekonstrukcja sygna³u 20 kHz przy próbkowaniu 48 kHz:
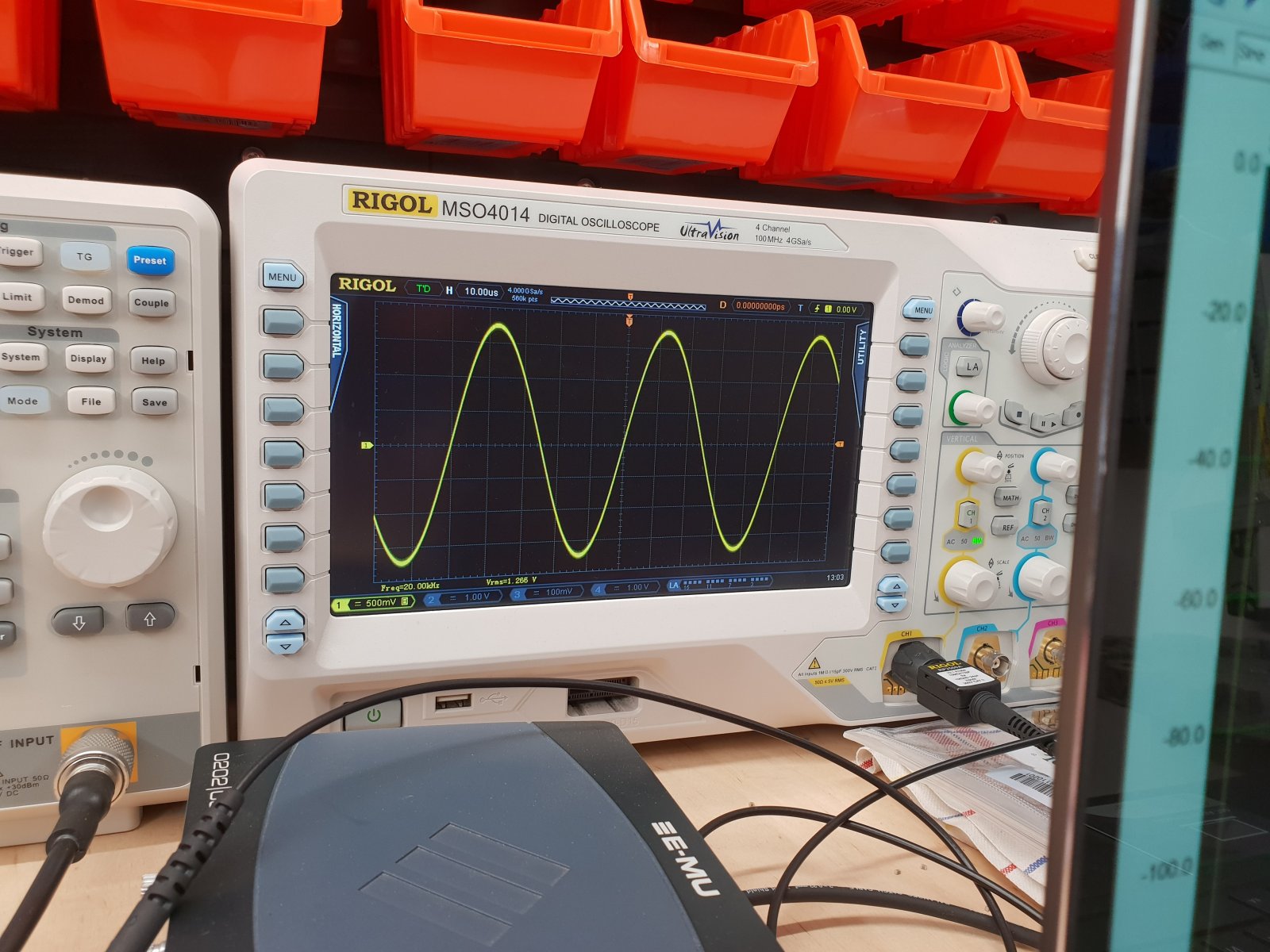
Inaczej mówi±c idealny sinus, czyli taki jaki powinien byæ.
Warto pokazaæ jak wygl±da sinus 10 kHz przy ekstrapolatorze rzêdu zerowego (NOS) oraz przy ekstrapolatorze rzêdu pierwszego (liniowa interpolacja), wiêc odpowiednio z mojego tematu o NOS DAC:
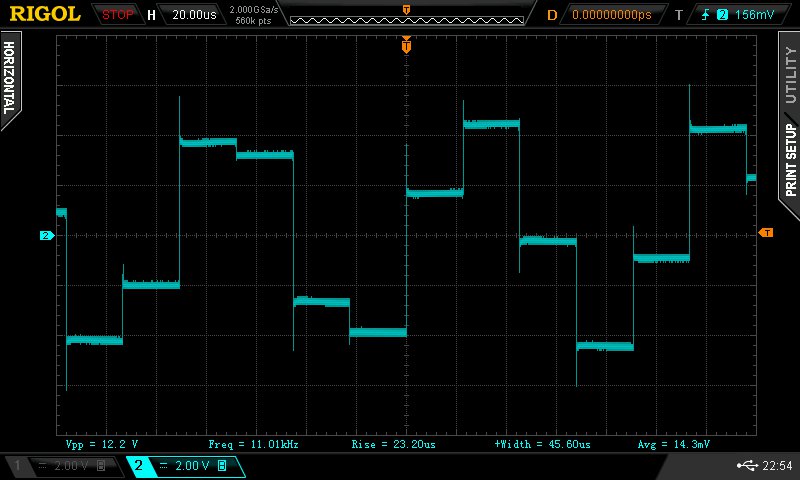
10 kHz i ekstrapolator rzêdu zerowego (R-2R, taki typowy NOS):
10 kHz i ekstrapolator rzêdu pierwszego (liniowa interpolacja):
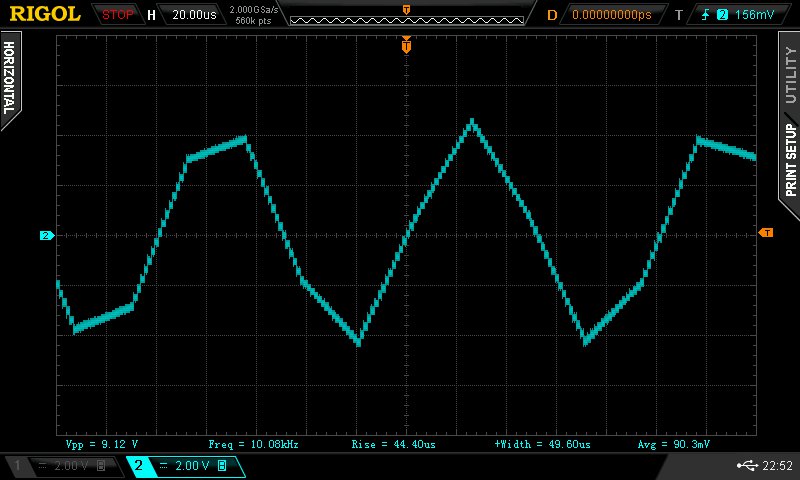
Jak widaæ takie przetworniki nie radz± sobie z filtrowaniem i odwzorowaniem sygna³u przy 10 kHz a gdzie tam do 20 kHz. Oczywi¶cie jest to ca³kowicie normalne, poniewa¿ taki by³ ich zarys dzia³ania, ale warto o tym wspomnieæ.
Tak samo odpowied¼ impulsowa filtru cyfrowego z tego tematu:
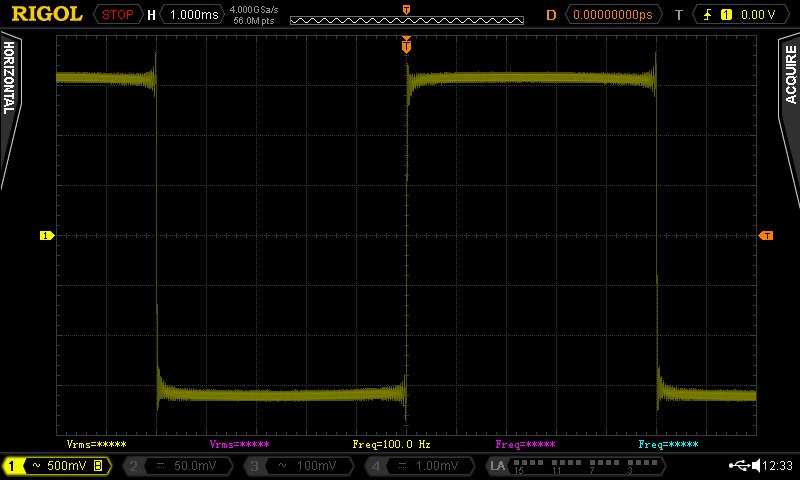
Tutaj widaæ lekkie "dzwonienie" od filtru cyfrowego i jest to ca³kowicie normalne, poniewa¿ pokazuje to, ¿e filtr ma ograniczone pasmo do rekonstrukcji sygna³u. Gdyby filtr by³ nieskoñczony tak jak funkcja sin(x) / x oraz jego pasmo by³oby nieskoñczone to byliby¶my w stanie idealnie odwzorowaæ prostok±t, ale po prostu nie ma takiej fizycznej mo¿liwo¶ci a nawet jakby by³a to skoñczyliby¶my na nieprawid³owo odwzorowanym sygnale audio :)
Filtr wygl±da jak poni¿ej:

Zworka ROM decyduje o tym jaki filtr za³adowaæ do g³ównej pamiêci RAM. Dostêpne s± dwa filtry, tj. o liniowej fazie oraz o minimalnej fazie. Oba s± rzêdu 8192 i fizycznie nie da siê wiêcej zmie¶ciæ :)
Dodatkowo DAC na AD1865 do tego projektu:

Przy okazji zaprojektowa³em te¿ specjaln± wersjê filtru pod TDA1541 oraz TDA1540:

W tym projekcie interpolacja jest 8-krotna oraz taktowanie przetwornika wygl±da trochê inaczej. Dodatkowo sam zegar CLK jest synchroniczny wzglêdem MCLK.
Podsumowuj±c g³ówne cechy mojego filtru s± nastêpuj±ce:
- Interpoluje do 705.6 kHz b±d¼ 768 kHz. Zawsze. Niezale¿nie od czêstotliwo¶ci wej¶ciowej, który mo¿e wahaæ siê od 44.1 kHz do 768 kHz.
- 8192 wspó³czynników w dwóch ró¿nych filtrach do wyboru (liniowa faza oraz minimalna faza).
- Asynchroniczny zegar taktuj±cy dane do przetwornika. Taki zabieg pozwala taktowaæ PCM56, AD1865 i podobne a¿ do 768 kHz :)
- Wewnêtrzne t³umienie o 1 dB.
- Jednostki mno¿±ce to 32x35 z akumulatorem 67-bitowym, wiêc s³owo audio jest akceptowane w pe³ni do 32 bitów rozdzielczo¶ci a wspó³czynniki maj± rozdzielczo¶æ 35 bitów. B³êdy kwantyzacja na tym poziomie s± ju¿ naprawdê minimalne.
- G³ówny rdzeñ pracuje przy czêstotliwo¶ci 225 MHz.
- Dithering TDPF.
- Wyj¶cie strumienia jest osobne dla kana³u L oraz R. Posiada tez odwrócone wyj¶cia, wiêc mo¿na pod³±czyæ przetworniki w formie ró¿nicowej.
- Wybór wyj¶ciowego s³owa od 16 do 24 bitów.
Rdzeñ pracuje przy takiej czêstotliwo¶ci, ¿e wymaga to dobrej znajomo¶ci budowy FPGA oraz idei przetwarzania potokowego (z ang. pipeliningu) a routowanie przy próbie spe³nienia wymagañ czasowych wygl±da nastêpuj±co:
[code]
PAR will use up to 4 processors
Starting Multi-threaded Router
Phase 1 : 11122 unrouted; REAL time: 3 secs
Phase 2 : 8282 unrouted; REAL time: 4 secs
Phase 3 : 2791 unrouted; REAL time: 6 secs
Phase 4 : 2921 unrouted; (Setup:10769, Hold:1222, Component Switching Limit:0) REAL time: 7 secs
Updating file: core.ncd with current fully routed design.
Phase 5 : 0 unrouted; (Setup:21621, Hold:581, Component Switching Limit:0) REAL time: 13 secs
Phase 6 : 0 unrouted; (Setup:20232, Hold:581, Component Switching Limit:0) REAL time: 15 secs
Phase 7 : 0 unrouted; (Setup:20232, Hold:581, Component Switching Limit:0) REAL time: 20 secs
Phase 8 : 0 unrouted; (Setup:20232, Hold:581, Component Switching Limit:0) REAL time: 20 secs
Phase 9 : 0 unrouted; (Setup:20232, Hold:581, Component Switching Limit:0) REAL time: 20 secs
Phase 10 : 0 unrouted; (Setup:20232, Hold:0, Component Switching Limit:0) REAL time: 20 secs
Phase 11 : 0 unrouted; (Setup:0, Hold:0, Component Switching Limit:0) REAL time: 20 secs
Total REAL time to Router completion: 20 secs
Total CPU time to Router completion (all processors): 33 secs [/code]
Inaczej mówi±c trzeba siê modliæ, ¿e warto¶ci Setup oraz Hold zostan± sprowadzone do zera
Projekt jest jeszcze w fazie rozwoju, wiêc pewne rzeczy mog± siê jeszcze zmieniæ. Na razie tyle, ale temat bêdzie kontynuowany
W sumie nie wiem od czego tu zacz±æ, poniewa¿ matematyka stoj±ca za cyfrowym filtrowaniem i ditheringiem nie bêdzie rozwijana, ale jednak trzeba co¶ wspomnieæ aby zrozumieæ dzia³anie filtrowania czêstotliwo¶ci w domenie cyfrowej. Zacznijmy jednak od tego, ¿e zadaniem takiego filtru jest dok³adnie takie same jak zwrotnicy w kolumnie g³o¶nikowej, tj. filtrowanie danych czêstotliwo¶ci i przepuszczanie innych
Ró¿nica jest jednak taka, ¿e taki filtr pracuje w domenie cyfrowej oraz ma zazwyczaj wysoki rz±d, tzw. du¿± ilo¶æ tapsów b±d¼ wspó³czynników. Taki filtr mo¿e byæ ka¿dego typu, tj. dolnoprzepustowy, górnoprzepustowy, ¶rodkowyprzepustowy czy jakikolwiek inny typ, tj. zale¿y to tylko i wy³±cznie od u¿ytych wspó³czynników. W tym wypadku bêdê skupiaæ siê na filtrze dolnoprzepustowym, poniewa¿ takim typu filtrem jest ten projekt.Pozwolê sobie zapo¿yczyæ grafikê filtru typu FIR aby wyjasniæ mniej wiêcej na jakiej zasadzie dzia³a taki filtr:
Mamy wej¶cie filtru, które w naszym wypadku jest wej¶ciem strumienia danych audio. Cz³on Z -1 to po prostu próbka audio opó¼niona o jeden, tj. ka¿da poprzednia próbka przed t± nowsz± (od najnowszej do najstarszej). Cz³ony Bx to wspó³czynniki filtru, które mno¿one s± poprzez wcze¶niejsze próbki ze strumienia audio. Wszystkie wyniki tych mno¿eñ s± potem dodawane do siebie i tak o to otrzymujemy próbkê na wyj¶ciu uk³adu
Najprostszym przyk³adem filtru FIR jest po prostu liczenie ¶redniej warto¶ci ze wszystkich poprzednich próbek. Zobaczmy na powy¿szy obrazek i za³ó¿my, ¿e wszystkie trzy cz³ony Bx maj± tak± sam± warto¶æ, tj. 1/3. Zak³adaj±c, ¿e na wej¶ciu uk³adu mamy próbki o warto¶ciach 1, 2 i 3 to matematyka stoj±ca za filtrem wygl±da nastêpuj±co: 1/3 * 1 + 1/3 * 2 + 1/3 * 3 = 2
Inaczej pisz±c w przypadku takich wspó³czynników liczymy tylko ¶redni± na bazie N próbek wej¶ciowych. Inn± nazw± takiego filtru to ¶rednia ruchoma, tj. z ang. moving-average (https://pl.wikipedia.org/wiki/¦rednia_ruchoma). Ciekawe jest to, ¿e taki filtr ju¿ kiedy¶ stworzy³em, ale nie sam filtr i nie cyfrowo, ale wbudowany w przetwornik D/A, tj. temat z "NOS" DAC:https://diyaudio.pl/showthread.php/2...-dobrze-zrobiæ
Przyk³adowy FIR oraz powy¿szy przetwornik D/A dzia³aj± dok³adnie tak samo, ale jeden dzia³a w domenie cyfrowej a drugi w analogowej
Taki filtr jest tzw. ekstrapolatorem rzêdu pierwszego. Niestety jego zdolno¶æ filtrowania i rekonstrukcji sygna³u pozostawia wiele do ¿yczenia, wiêc jest to generalnie tylko ciekawostka, ale ma te¿ swoje plusy (szczególnie przy strumieniu DSD). My¶lê, ¿e warto tutaj wspomnieæ te¿ o tym, ¿e ekstrapolatorem rzêdu zerowego jest zwyczajny przetwornik R-2R w formie NOS Poni¿szy obrazek przedstawia ró¿nicê miêdzy ekstrapolatorem rzêdu zerowego (NOS) a ekstrapolatorem rzêdu pierwszego (liniowa interpolacja) oraz ich odpowiedzi impulsowe wraz z charakterystyk± czêstotliwo¶ciow±:Naprawdê nie ma co siê rozpisywaæ, poniewa¿ pisanie o filtrach FIR mo¿e i byæ ciekawe, ale zbêdne i czasoch³onne. Temat dotyczy samego projektu takiego filtru a nie tego jaka matematyka za tym wszystkim stoi, wiêc postaram siê jeszcze po szybko¶ci wspomnieæ o interpolacji, filtrowaniu sin(x) / x i ditheringu oraz przej¶æ do samego projektu filtru na FPGA.
W nazwie temat wspomnia³em, ¿e zaprojektowany filtr cyfrowy jest typu interpolacyjnego, tj. takiego, który zwiêksza oryginaln± czêstotliwo¶æ próbkowania, przyk³adowo 44.1 kHz, do zadanej czêstotliwo¶ci, np. w moim wypadku jest to 705.6 kHz. Z prostej matematyki mo¿na wywnioskowaæ, ¿e filtr interpoluje 16-krotnie (44.1 kHz * 16 = 705.6 kHz). Zacznijmy jednak od tego co to jest interpolacja. Interpolacja jest to proces wyznaczenia pewnej funkcji, która przyjmuje takie same warto¶ci w zadanej przedziale w którym s± ju¿ wyznaczone pewne punkty. Sygna³ audio zapisany jest jako warto¶æ amplitudy (punkt na osi Y) w pewnych odstêpach czasowych (o¶ X, np. 44.1 kHz). Inaczej pisz±c zadaniem interpolacji jest po prostu wyznaczenie dodatkowych punktów pomiêdzy istniej±cymi ju¿ punktami. Taki zabieg najlepiej przedstawiæ na obrazku, wiêc zobaczmy poni¿ej:
Czerwony to sygna³ taki jaki mamy zapisany w pliku i zrekonstruowany na przetworniku R-2R w formie NOS (ekstrapolator rzêdu zerowego). Czarny to ten sam sygna³, ale interpolowany do nieskoñczenie wy¿szej czêstotliwo¶ci w celu odtworzenia wiêkszej ilo¶ci punktów oryginalnego zapisu. Inaczej pisz±c taki zabieg w praktyce to po prostu rekonstrukcja sygna³u wraz z filtrowaniem dolnoprzepustowym. Interpolacja w formie cyfrowej to dwa zabiegi, tj. wrzucenie próbek o zerowej amplitudzie do sygna³u tak aby zwiêkszyæ czêstotliwo¶æ oraz filtrowanie dolnoprzepustowe w celu pozbycia siê odbiæ sygna³u, które powsta³y z powodu zwiêkszenia próbkowania. Na poni¿szych obrazkach mo¿na zobaczyæ jak to w praktyce wygl±da:
W pierwszym obrazku na samej górze posiadamy sygna³ oryginalny, dyskretny (czarne punkty) oraz ci±g³y (szara linia). Sygna³u w formie ci±g³ej nie da siê zapisaæ, poniewa¿ wymaga³oby to nieskoñczonej ilo¶ci miejsca, wiêc w praktyce zapisujemy tylko sygna³ w formie dyskretnej (próbkowany w równych odstêpach czasu, np. 44.1 kHz). W celu odtworzenia oryginalnego sygna³u musimy zwiêkszyæ ilo¶æ próbek, które pozwol± nam zamieniæ sygna³y dyskretny na sygna³ ci±g³y (analogowy). W tym celu wrzucamy próbki o warto¶ci 0 pomiêdzy ju¿ istniej±ce próbki (drugi wykres). Taki zabieg pozwoli³ nam faktycznie zwiêkszyæ próbkowania, ale niestety wprowadzi³ te¿ odbicia sygna³u. W praktyce podczas próby odtworzenia takiego sygna³u otrzymujemy sygna³ powielony wzglêdem "lustra", które tworzy siê na wielokrotno¶ci oryginalnej czêstotliwo¶ci próbkowania (44.1 kHz). Ten problem mo¿na zobaczyæ na drugim obrazku po prawej stronie gdzie widnieje wykres w domenie czêstotliwo¶ciowej. W celu eliminacji tych odbiæ stosuje siê filtrowanie dolnoprzepustowe, które w praktyce przesuwa odbicia na wy¿sz± czêstotliwo¶æ gdzie mo¿na ju¿ spokojnie filtrowaæ filtrem analogowym z niskim rzêdem. Inaczej pisz±c czym wiêksza interpolacja tym dalej przesuwane s± odbicia oryginalnego sygna³u.
No i w sumie to tyle wystarczy na temat samej interpolacji, wiêc na szybko¶ci przejd¼my jeszcze do filtrowania dolnoprzepustowego funkcj± sin(x) / x. W przetwarzaniu sygna³u u¿ywa siê tylko funkcji sin(x) / x do filtrowania dolnoprzepustowego, poniewa¿ z matematycznego punktu widzenia jest ona idealnym filtrem dolnoprzepustowym (z ang. brick-wall). Wynika to z faktu, ¿e odpowied¼ czêstotliwo¶ciowa funkcji sin(x) / x jest funkcj± prostok±tn±:
Oznacza to w praktyce tyle, ¿e przepuszcza idealnie zadane czêstotliwo¶ci a wszystkie poza wyznaczon± odpowiedzi± czêstotliwo¶ciow± po prostu usuwa. Normalnie idealny filtr, ale nie ma tak ³atwo
Niestety funkcja sin (x) / x jest nieskoñczona, wiêc nie da siê jej przedstawiæ w formie praktycznego filtru cyfrowego. W tym celu u¿ywa siê metody tzw. okna czasowego (z ang. windowing), który pozwala nam "wygasiæ" funkcjê po pewnym okresie, która w praktyce jest nieskoñczona. Przyk³adowo tak± funkcj± okna czasowego mo¿e byæ okno Kaisera (ja takiego u¿y³em do wyznaczenia wspó³czynników mojego filtru sin (x) / x). Okno Kaisera wygl±da jak na poni¿szym obrazku:Teraz zobaczmy sobie co takie okno czasowe mo¿e zdzia³aæ z nieskoñczona funkcj± sin (x) / x:
Czerwony wykres - okno czasowe.
Zielony wykres - nieskoñczona funkcja sin(x) / x.
Niebieski wykres - funkcja sin(x) / x po zastosowaniu okna czasowego.
Taki zabieg w praktyce pozwala zastosowaæ funkcjê sin(x) / x do filtrowania
Oczywi¶cie wprowadza to pewne b³êdy filtrowania i taki filtr nigdy nie bêdzie idealny jak sama funkcja sin(x) / x, ale zwiêkszaj±c ilo¶æ wspó³czynników (dyskretnie zapisanego sygna³u sin(x) / x po oknie czasowym) mo¿na d±¿yæ do tej idealnej odpowiedzi czêstotliwo¶ciowej. Niestety trzeba te¿ pamiêtaæ o tym, ¿e w praktyce mamy ograniczon± ilo¶æ pamiêci w której mo¿emy zapisaæ wspó³czynniki, wiêc wprowadza to dodatkowe b³êdy kwantyzacji (cyt. "nieodwracalne nieliniowe odwzorowanie statyczne zmniejszaj±ce dok³adno¶æ danych przez ograniczenie ich zbioru warto¶ci").No i mo¿na zacz±æ filtrowaæ! No prawie, poniewa¿ jako, ¿e pracujemy na dyskretnych sygna³ach a nie na ci±g³ych i do tego jeszcze mamy do czynienia z b³êdami kwantyzacji to jeszcze dosyæ wa¿n± rzecz± przy takim projekcie jest tzw. dithering podczas redukcji bitów wyj¶ciowego s³owa. Dlaczego redukcji? W praktyce nasz przetwornik D/A operuje przyk³adowo na s³owach audio o d³ugo¶ci 18 bitów. Zak³adaj±c, ¿e nasze s³owo wej¶ciowe to 24 bitowy sygna³ audio oraz sam fakt, ¿e te s³owo przechodzi filtrowanie w którym wystêpuje mno¿enie, powoduje, ¿e zale¿nie od ilo¶ci bitów wspó³czynników filtru, które mog± przyk³adowo mieæ 32 bity, otrzymujemy wynik na poziomie 56 bitów. No dobra, ale mno¿ymy 24 bitow± liczbê przez 32 bitow± liczbê, wiêc jakim cudem mamy wynik na 56 bitach? Taka po prostu jest matematyka
Mno¿±c dwie liczby X oraz Y o d³ugo¶ci bitów odpowiednio 24 oraz 32 wynik tego zabiegu wymaga 56 bitów do zapisu. Zreszt±, nawet jakby¶my nie musieli nic mno¿yæ to i tak musimy zredukowaæ 24 bity do 18 bitów, które przyjmuje przetwornik. Taki zabieg jest wymagany, poniewa¿ b³êdy kwantyzacji sygna³u wprowadzane przez redukcjê bitów (np. uciêcie ostatnich bitów) s± wprowadzane w sam sygna³ audio. Dither to najprostsza metoda przeniesienia energii tych b³êdów kwantyzacji na losowy szum w sygnale audio. Inaczej pisz±c specjalnie dodajemy szum do sygna³u audio Najlepiej bêdzie to pokazaæ na przyk³adzie:Bez ditheringu:
Z ditheringiem:
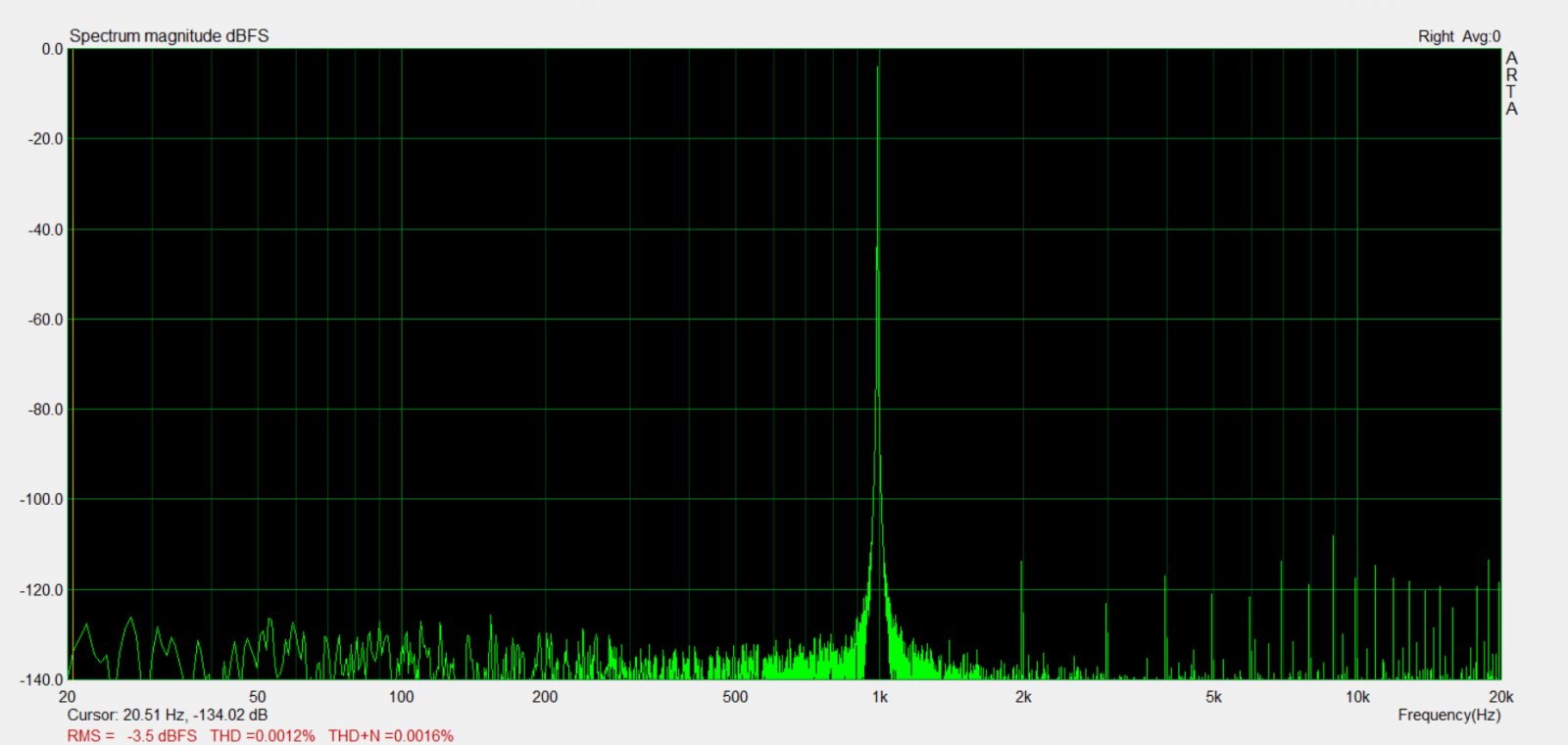
Na przyk³adzie tego filtra zosta³o pokazane jak dither mo¿e pomóc przy odwzorowaniu sygna³u -96 dBFS na 18 bitowym przetworniku :) Na górze te¿ jest ¶rednia z 10 pomiarów, wiêc koniec koñców ró¿nica w szumie jest ¿adna :)
Dithering wymaga generatora liczb pseudolosowych, poniewa¿ chcemy aby nasz szum by³ po prostu losowy. No prawie, poniewa¿ nie potrzebujemy losowo¶ci w sensie nieprzewidywalno¶ci samych generowanych liczb, ale ci±gu generowanych warto¶ci, które maj± rozk³ad jednostajnie ci±g³y, tj. taki dla którego wyst±pienie danej liczby z danego przedzia³u jest tak samo prawdopodobne jak dla ka¿dej innej z tego samego przedzia³u. Pewn± w³asno¶ci± rozk³adu jednostajnie ci±g³ego jest to, ¿e dodanie dwóch takich losowych liczb zamienia rozk³ad na trójk±tny, czyli taki, którego gêsto¶æ prawdopodobieñstwa rozk³ada siê w formê trójk±tn± gdzie jego wierzcho³ek to liczby, które maj± najwiêksz± szansê na trafienie. Na poni¿szym obrazku X oraz Y to rozk³ad jednostajnie ci±g³y a Z to trójk±tny:
Rozk³ad trójk±tny jest ¶wietny do ditheringu audio, poniewa¿ zazwyczaj maj±c jedynkê chcemy aby dalej to by³a jedynka, tj. z du¿ym prawdopodobieñstwem, ale aby nie by³o to równomierne. Inaczej pisz±c ditheringiem mo¿na nazwaæ operacjê posiadania liczby X oraz losowania liczby Y chc±c trafiæ tak, aby X ~ Y, ale jednak nie chcemy znanej liczby X, ale nowej liczby Y, która ma du¿e prawdopodobieñstwo trafiæ blisko X
¬ród³em takiej pseudo losowo¶ci do wygenerowania rozk³adu trójk±tnego w FPGA mo¿e byæ rejestr przesuwaj±cy z liniowym sprzê¿eniem zwrotnym, który tak¿e zosta³ zaimplementowany w tym projekcie. Zaimplementowany rejestr ma okres 2^47 i pracuje z zegarem MCLK, który mo¿e tykaæ z czêstotliwo¶ci± do 49.152 MHz. Z prostej matematyki wynika, ¿e taki rejestr zanim zacznie siê powtarzaæ z liczbami to minie ponad miesi±c ci±g³ej pracy, wiêc tym bardziej jest wystarczaj±cy do generowania pseudo losowych warto¶ci
Zreszt±, po pomiarach z ditherem i bez mo¿na jasno wywnioskowaæ, ¿e losowo¶æ spe³nia pewne wymogi i energia b³êdu kwantyzacji jest zamieniana na energiê szum.No dobra, mo¿e koniec ju¿ samej teorii. My¶la³em, ¿e skrócê to wszystko dosyæ znacz±co omijaj±c pewne rzeczy, ale teraz jak na to patrzê to widzê, ¿e nawet mocno skrócony opis potrafi byæ rozleg³y w takiej tematyce.
_____________________________________
W ka¿dym wypadku przejd¼my do samego projektu filtru, który zosta³ zaimplementowany w FPGA (bezpo¶rednio programowalna macierz bramek) w formie RTL (opisu sprzêtu w formie logiki w VHDL'u). FPGA u¿yte w tym projekcie to Spartan-6 XC6SLX9 w obudowie TQFP-144. W innych projektach zazwyczaj u¿ywam Spartan-3 XC3S50AN, poniewa¿ posiadam ich jeszcze trochê i sobie ceniê ich prostotê oraz wbudowany FLASH do konfiguracji. Niestety do tego projektu taki Spartan-3 jest po prostu za s³aby i nie posiada odpowiednich jednostek do implementacji sensownego filtru cyfrowego. Pewnie, jaki¶ filtr mo¿na tam zmie¶ciæ, ale po co tworzyæ nastêpne dziadostwo, które w sumie nie wiele wiêcej wprowadza ni¿ gotowe uk³ady dostêpne na rynku od lat 90. Zaprojektowany filtr implementuje zarówno interpolacjê jak i decymacjê. Matematycznie wykonuje on 16-krotn± interpolacjê dla ka¿dej wej¶ciowej czêstotliwo¶ci (tj. od 44.1 kHz do 768 kHz). W praktyce wygl±da to tak, ¿e sygna³ 768 kHz te¿ jest interpolowany 16-krotnie (do 12.288 MHz), ale koniec koñców sygna³ jest decymowany do zadanej warto¶ci (odrzucanie próbek). Operacja interpolacji i decymacji na tych samych wspó³czynnikach skraca siê, wiêc w praktyce to wygl±da tak, ¿e filtr nie liczy próbek, które i tak zostan± odrzucone
Na rynku mamy wiele uk³adów filtrów cyfrowych takich jak SAA7220, DF1706, SM5847, itp. Wszystkie te uk³ady s³u¿± do tego samego, tj. interpolacji sygna³u audio. W praktyce niektóre s± lepsze a niektóre gorsze, wiêc ka¿dy bêdzie gra³ inaczej. Przyk³adowo SAA7220 jest chyba najlepszym przyk³adem kiepskiego filtru zrobionego po tanio¶ci
Wspó³czynniki 12-bitowe, s³owo wej¶ciowe maksymalnie do 16 bitów, bardzo ma³y akumulator (du¿o b³êdów zaokr±glenia wyników mno¿enia) oraz brak ditheringu. Ewidentnie widaæ, ¿e to co stracimy w kiepskim filtrze cyfrowym na pewno nie uda nam siê nadrobiæ przetwornikiem D/A. Filtry cyfrowe takie jak DF1706 czy SM5847 s± ju¿ znacz±co lepsze i to widaæ, ale ich kaskadowana interpolacja na ró¿nych wspó³czynnikach raczej do mnie nie przemawia. Filtr taki jak SM5847 interpoluje 8-krotnie w 3 fazach, tj. pierwsza faza posiada 169 wspó³czynników (fs do 2fs), druga faza ju¿ tylko 29 wspó³czynników (2fs do 4fs) oraz ostatnia faza z 17 wspó³czynnikami (4fs do 8fs). Tak po prostu ³atwiej by³o go zaprojektowaæ, ale niekoniecznie lepiej sonicznie. Filtr cyfrowy przedstawiony w tym temacie interpoluje i decymuje na tych samych wspó³czynnikach, wiêc nie wa¿ne jaka jest czêstotliwo¶æ wej¶ciowa to zawsze te same wspó³czynniki u¿ywane s± do stworzenia wyj¶ciowego strumienia Mój filtr ma sta³± warto¶æ polifazy oraz interpolacji, która wynosi 16. Oznacza to w sumie tyle, ¿e ka¿da nowa próbka audio tworzona jest na bazie 512 poprzednich próbek (8192 / 16 = 512). Sygna³ powinien byæ perfekcyjnie zrekonstruowany na bazie poprzednich próbek.W danej chwili wspó³czynniki filtru wraz z u¿ytym oknem oraz pasmem przepustowym wygl±daj± nastêpuj±co:
Trzeba pamiêtaæ, ¿e filtr jest interpolacyjny, wiêc pasmo przepustowe liczy siê na bazie docelowej czêstotliwo¶ci.
W praktyce nie ma co siê do tych wspó³czynników przywi±zywaæ, poniewa¿ zale¿nie od sonicznych do¶wiadczeñ mo¿na w chwilê za³adowaæ nowe i znowu ods³uchiwaæ
Poni¿ej parê zdjêæ, które ju¿ wrzuca³em w budowanie na ekranie, ale warto te¿ pokazaæ je w tym temacie:
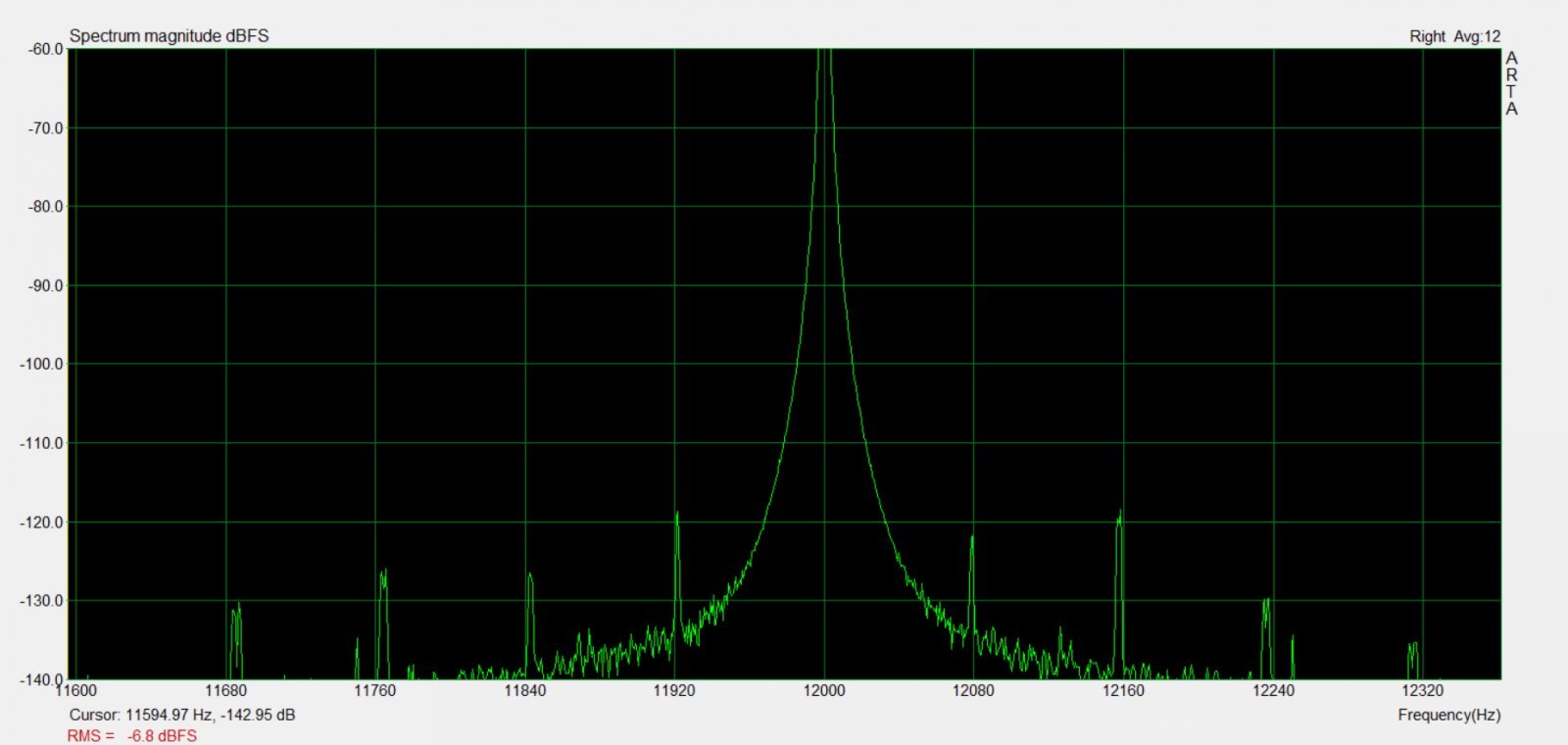
Rekonstrukcja sygna³u 20 kHz przy próbkowaniu 48 kHz:
Inaczej mówi±c idealny sinus, czyli taki jaki powinien byæ.
Warto pokazaæ jak wygl±da sinus 10 kHz przy ekstrapolatorze rzêdu zerowego (NOS) oraz przy ekstrapolatorze rzêdu pierwszego (liniowa interpolacja), wiêc odpowiednio z mojego tematu o NOS DAC:
10 kHz i ekstrapolator rzêdu zerowego (R-2R, taki typowy NOS):
10 kHz i ekstrapolator rzêdu pierwszego (liniowa interpolacja):
Jak widaæ takie przetworniki nie radz± sobie z filtrowaniem i odwzorowaniem sygna³u przy 10 kHz a gdzie tam do 20 kHz. Oczywi¶cie jest to ca³kowicie normalne, poniewa¿ taki by³ ich zarys dzia³ania, ale warto o tym wspomnieæ.
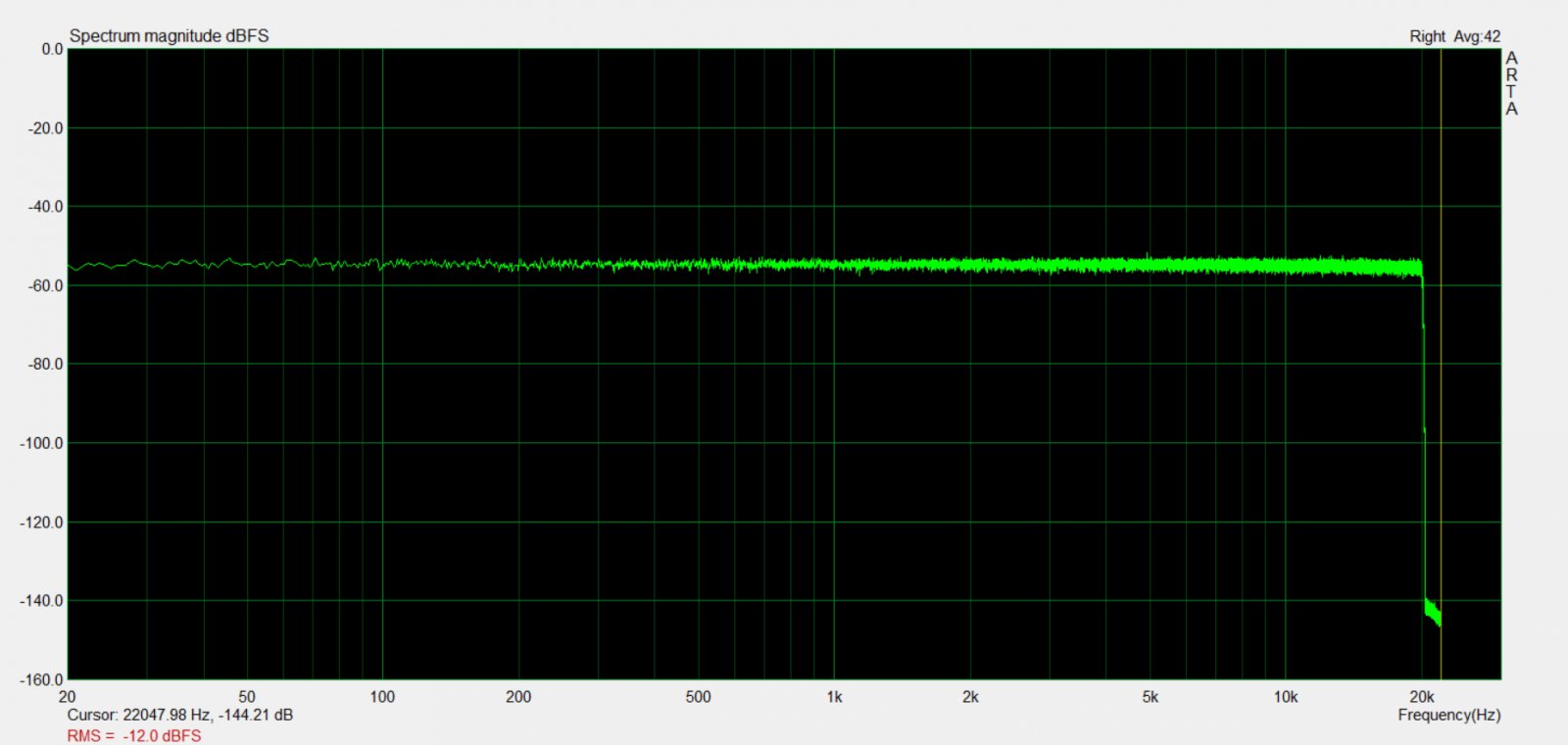
Tak samo odpowied¼ impulsowa filtru cyfrowego z tego tematu:
Tutaj widaæ lekkie "dzwonienie" od filtru cyfrowego i jest to ca³kowicie normalne, poniewa¿ pokazuje to, ¿e filtr ma ograniczone pasmo do rekonstrukcji sygna³u. Gdyby filtr by³ nieskoñczony tak jak funkcja sin(x) / x oraz jego pasmo by³oby nieskoñczone to byliby¶my w stanie idealnie odwzorowaæ prostok±t, ale po prostu nie ma takiej fizycznej mo¿liwo¶ci a nawet jakby by³a to skoñczyliby¶my na nieprawid³owo odwzorowanym sygnale audio :)
Filtr wygl±da jak poni¿ej:
Zworka ROM decyduje o tym jaki filtr za³adowaæ do g³ównej pamiêci RAM. Dostêpne s± dwa filtry, tj. o liniowej fazie oraz o minimalnej fazie. Oba s± rzêdu 8192 i fizycznie nie da siê wiêcej zmie¶ciæ :)
Dodatkowo DAC na AD1865 do tego projektu:
Przy okazji zaprojektowa³em te¿ specjaln± wersjê filtru pod TDA1541 oraz TDA1540:
W tym projekcie interpolacja jest 8-krotna oraz taktowanie przetwornika wygl±da trochê inaczej. Dodatkowo sam zegar CLK jest synchroniczny wzglêdem MCLK.
Podsumowuj±c g³ówne cechy mojego filtru s± nastêpuj±ce:
- Interpoluje do 705.6 kHz b±d¼ 768 kHz. Zawsze. Niezale¿nie od czêstotliwo¶ci wej¶ciowej, który mo¿e wahaæ siê od 44.1 kHz do 768 kHz.
- 8192 wspó³czynników w dwóch ró¿nych filtrach do wyboru (liniowa faza oraz minimalna faza).
- Asynchroniczny zegar taktuj±cy dane do przetwornika. Taki zabieg pozwala taktowaæ PCM56, AD1865 i podobne a¿ do 768 kHz :)
- Wewnêtrzne t³umienie o 1 dB.
- Jednostki mno¿±ce to 32x35 z akumulatorem 67-bitowym, wiêc s³owo audio jest akceptowane w pe³ni do 32 bitów rozdzielczo¶ci a wspó³czynniki maj± rozdzielczo¶æ 35 bitów. B³êdy kwantyzacja na tym poziomie s± ju¿ naprawdê minimalne.
- G³ówny rdzeñ pracuje przy czêstotliwo¶ci 225 MHz.
- Dithering TDPF.
- Wyj¶cie strumienia jest osobne dla kana³u L oraz R. Posiada tez odwrócone wyj¶cia, wiêc mo¿na pod³±czyæ przetworniki w formie ró¿nicowej.
- Wybór wyj¶ciowego s³owa od 16 do 24 bitów.
Rdzeñ pracuje przy takiej czêstotliwo¶ci, ¿e wymaga to dobrej znajomo¶ci budowy FPGA oraz idei przetwarzania potokowego (z ang. pipeliningu) a routowanie przy próbie spe³nienia wymagañ czasowych wygl±da nastêpuj±co:
[code]
PAR will use up to 4 processors
Starting Multi-threaded Router
Phase 1 : 11122 unrouted; REAL time: 3 secs
Phase 2 : 8282 unrouted; REAL time: 4 secs
Phase 3 : 2791 unrouted; REAL time: 6 secs
Phase 4 : 2921 unrouted; (Setup:10769, Hold:1222, Component Switching Limit:0) REAL time: 7 secs
Updating file: core.ncd with current fully routed design.
Phase 5 : 0 unrouted; (Setup:21621, Hold:581, Component Switching Limit:0) REAL time: 13 secs
Phase 6 : 0 unrouted; (Setup:20232, Hold:581, Component Switching Limit:0) REAL time: 15 secs
Phase 7 : 0 unrouted; (Setup:20232, Hold:581, Component Switching Limit:0) REAL time: 20 secs
Phase 8 : 0 unrouted; (Setup:20232, Hold:581, Component Switching Limit:0) REAL time: 20 secs
Phase 9 : 0 unrouted; (Setup:20232, Hold:581, Component Switching Limit:0) REAL time: 20 secs
Phase 10 : 0 unrouted; (Setup:20232, Hold:0, Component Switching Limit:0) REAL time: 20 secs
Phase 11 : 0 unrouted; (Setup:0, Hold:0, Component Switching Limit:0) REAL time: 20 secs
Total REAL time to Router completion: 20 secs
Total CPU time to Router completion (all processors): 33 secs [/code]
Inaczej mówi±c trzeba siê modliæ, ¿e warto¶ci Setup oraz Hold zostan± sprowadzone do zera
Projekt jest jeszcze w fazie rozwoju, wiêc pewne rzeczy mog± siê jeszcze zmieniæ. Na razie tyle, ale temat bêdzie kontynuowany







Skomentuj